
PROTECT YOUR DNA WITH QUANTUM TECHNOLOGY
Orgo-Life the new way to the future Advertising by Adpathway

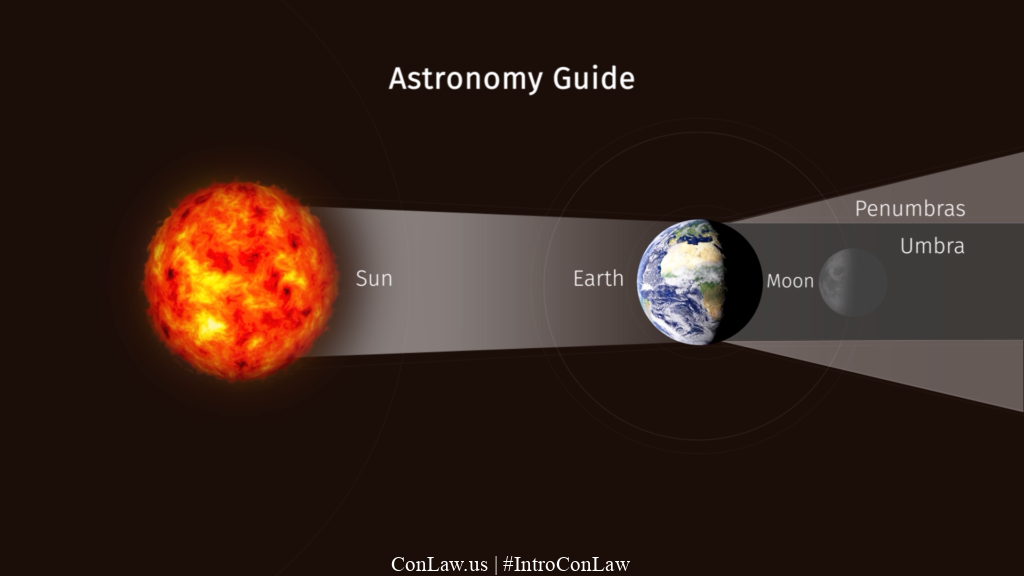
[Regarding: https://www.metabunk.org/threads/digitized-sky-survey-poss-1.14385/]
Quick methodological question: is this a rigorous replication attempt or exploratory analysis? I ask because the approach will matter for interpreting findings.
If it's rigorous replication: Should pre-register methodology upfront (exact data sources, processing pipeline with parameters, statistical tests, and decision criteria.) GitHub repo with timestamped protocol is standard for computational reproducibility. This allows findings to actually challenge or support Villarroel's claims.
If it's exploratory analysis, pre-registration isn't necessary, but findings should be framed as "here's what we found exploring the data" rather than "we attempted replication and here's the definitive result."
Either approach is valid, but they require different standards and produce different levels of confidence in conclusions. Which mode is this thread in?
Last edited by a moderator: Today at 12:39 PM

Quick methodological question: is this a rigorous replication attempt or exploratory analysis? I ask because the approach will matter for interpreting findings.
If it's rigorous replication: Should pre-register methodology upfront (exact data sources, processing pipeline with parameters, statistical tests, and decision criteria.) GitHub repo with timestamped protocol is standard for computational reproducibility. This allows findings to actually challenge or support Villarroel's claims.
If it's exploratory analysis, pre-registration isn't necessary, but findings should be framed as "here's what we found exploring the data" rather than "we attempted replication and here's the definitive result."
Either approach is valid, but they require different standards and produce different levels of confidence in conclusions. Which mode is this thread in?
I'm working on exploratory analysis based on the workflow description of the 2022 paper: https://academic.oup.com/mnras/article/515/1/1380/6607509?login=false because it is the only paper that describes the software with enough details.
The idea is to learn how this can be done, because I've not done this kind of stellar image analysis with software before. It seems doable: I can already download single 30x30 arcmin FITS file and run it through SExtractor and stilts/cdsskymatch. But the tessellation of all POSS-I red images is a difficult task probably due to lack of experience. If I manage to get it working, similar (or perhaps the same) pipeline could be used to replicate the findings of two new papers (PASP, SciRep), including Earth shadow and other calculations.

Should pre-register methodology upfront (exact data sources, processing pipeline with parameters, statistical tests, and decision criteria.)
Villarroel didn't do this, did she?
It's kinda useless when working with historical data, because you can run your analysis, then register, and then run the analysis again.
Pre-registration is only valid when data gathering is involved.
Villarroel didn't do this, did she?
It's kinda useless when working with historical data, because you can run your analysis, then register, and then run the analysis again.
Pre-registration is only valid when data gathering is involved.
That's not quite right. Pre-registration prevents p-hacking, HARKing, and selective reporting - all of which are just as possible (arguably more so) with historical data as with new data collection. The concern isn't "someone might cheat and pre-register after running analysis." The concern is analysts running multiple tests until finding significance, then claiming that test was their hypothesis all along. Pre-registration creates a public record of what was planned before seeing results.
You're right that Villarroel didn't pre-register; that's a limitation of her work. But "she didn't do it either" doesn't make it less important for rigorous replication. If the goal is to demonstrate her findings don't hold up to proper scrutiny, that means applying standards she didn't meet - not matching her limitations.
So...if findings from this thread are framed as definitive replication/refutation rather than exploratory analysis, they'll be vulnerable to the same methodological critiques being made of Villarroel.

So...if findings from this thread are framed as definitive replication/refutation rather than exploratory analysis, they'll be vulnerable to the same methodological critiques being made of Villarroel.
I think [that] thread should aim for a trivially replicable and improvable analysis. Arguing about p-hacking is an off-topic distraction. If there's p-hacking, then a fully open approach will reveal it.
Last edited: Today at 12:42 PM
The concern is analysts running multiple tests until finding significance, then claiming that test was their hypothesis all along. Pre-registration creates a public record of what was planned before seeing results.
My concern is analysts running multiple tests until finding significance, registering the test that worked out, then running it again and claiming that test was their hypothesis all along.
When you have research that gathers fresh data, then data gathering after registration removes this concern, but registration does nothing for analysis of historical data that you have already on file.
What helps here is being transparent about your choices.
I think this thread should aim for a trivially replicable and improvable analysis. Arguing about p-hacking is an off-topic distraction. If there's p-hacking, then a fully open approach will reveal it.
@Mick West - I'm not arguing you're p-hacking. I'm pointing out that without pre-registration, any findings will be vulnerable to that critique, and legitimately so. Open code shows what analysis was run, but not how many were tried first. If 10 approaches are tested and the one showing significance is reported, the code for that approach looks fine...but it's still p-hacking. Pre-registration distinguishes "this is what we predicted and tested" from "this is what we found after trying multiple things." That's not a distraction - it's the difference between exploratory analysis (which is fine if framed honestly) and rigorous replication (which requires committing to methodology upfront).
If findings are presented as definitive replication/refutation without pre-registration, they'll be eclipsed by methodological critiques - the same ones being made of Villarroel.
I realize the group here doesn't want to take this approach, and I'll rest my point here. But I reserve the right to say I told you so later. 

@Mick West - I'm not arguing you're p-hacking.
Noone said you were, [...]
I'm pointing out that without pre-registration, any findings will be vulnerable to that critique, and legitimately so.
You're overlooking the fact that in order to preregister this, you'd need a time machine to take you back 70 years, before the data was gathered. There's no new information content in recycled data, there's no unpredictability, every outcome, for any of our chosen inputs, is purely deterministic now. You're advocating a method that, misused the way you want us to misuse it - /post facto/, incentivises cherry picking a preregistration that we know leads to the outcome that would support our priors. That's the opposite of good science. [...]
Last edited by a moderator: Today at 12:41 PM
@Mick West - I'm not arguing you're p-hacking. I'm pointing out that without pre-registration, any findings will be vulnerable to that critique, and legitimately so. Open code shows what analysis was run, but not how many were tried first. If 10 approaches are tested and the one showing significance is reported, the code for that approach looks fine...but it's still p-hacking. Pre-registration distinguishes "this is what we predicted and tested" from "this is what we found after trying multiple things." That's not a distraction - it's the difference between exploratory analysis (which is fine if framed honestly) and rigorous replication (which requires committing to methodology upfront).
If findings are presented as definitive replication/refutation without pre-registration, they'll be eclipsed by methodological critiques - the same ones being made of Villarroel.
I realize the group here doesn't want to take this approach, and I'll rest my point here. But I reserve the right to say I told you so later.
I think a general concern of the group is that the paper's conclusions rely on a series of inferences based on a series of disputable (and often disputed) standards:
- Their definition of what counts as a glint and their dismissal of other researchers' interpretations of those spots as potential emulsion defects. The inference here is that these spots can't be from other causes and must be from reflective objects high in the atmosphere or in orbit.
- Their envelope for "in a line" for transients being in a line seems somewhat generous. Even if someone can reproduce their methodology, the ranges here are a choice. There is also an arbitrary choice that the intervals don't have to be regular; that there could be objects that glint at irregular intervals, so the spacing of dots and length of a line are arbitrary.
- The statistical correlations are rather loose. Sure, they chose a +/- 1 day window for associating detonation dates with glints before running the numbers, but the lack of precision about time zones and what time during a day a glint or explosion happened means the windows cover ~96 to 120 hours. When we're talking about a period of time when detonations happened an average of every 528 hours (one per 22 days), that interval seems generous. If more precise times aren't available, that limits the value of any conclusions.
- The analysis should also incorporate the dates for when detonations were scheduled, but not conducted (which happened due to technical and weather reasons), since there is no meaningful difference. (It might be worth splitting the analysis into two groups -- did transients appear before the day of a scheduled test, or not? Which would be a much larger set of dates.) If the data is not available, that limits the value of any conclusions.
- It's even more generous when you consider they don't control for the external correlations between the data sets -- both the blasts and the survey dates are influenced by human schedules, and the survey plates are not a random or representative sampling of the skies during the years in question.
- I'm not even going to delve into the messiness of the UAP report data, which is at best not a random or representative sample.
So another researcher, or someone here on Metabunk, might be able to replicate their identification of transients using their methods, but what people are questioning is whether those methods and their association with other events choose to give too much weight to imprecise and incomplete data.
There is also an arbitrary choice that the intervals don't have to be regular; that there could be objects that glint at irregular intervals, so the spacing of dots and length of a line are arbitrary.
that's not an arbitrary choice, it's the only choice that yields result.
We can surmise that it was made after data exploration.
83 satellite candidates, and apparently none of them rotates periodically.
If they had pre-registered on that, they'd fail.
Their definition of what counts as a glint and their dismissal of other researchers' interpretations of those spots as potential emulsion defects.
My problem is that Villarroel and Solano are dismissing their own identification of many of these transients in the 2022 paper.
I really like that older paper. It's straightforward and transparent, a lot of astronomical knowledge went into it, and it went very far. One could say it didn't go far enough, but they published their resulting dataset, so anyone else could take it from there; and I think that's ok.
The new papers are a big step backwards, in several aspects.










.jpg)






 English (US) ·
English (US) ·  French (CA) ·
French (CA) ·